
Apache Hadoop has emerged as a cornerstone technology in the realm of big data processing, revolutionizing how organizations manage and analyze vast amounts of information. Initially developed by Doug Cutting and Mike Cafarella in 2005, Hadoop was inspired by Google’s MapReduce and Google File System (GFS) papers. Its open-source nature has allowed it to evolve rapidly, garnering a robust community of developers and users who contribute to its ongoing enhancement.
Today, Hadoop is synonymous with big data, providing a framework that enables the distributed processing of large data sets across clusters of computers using simple programming models. At its core, Apache Hadoop is designed to handle massive volumes of data efficiently and cost-effectively. It allows organizations to store and process data in a distributed manner, breaking down large tasks into smaller, manageable pieces that can be executed in parallel.
This capability is particularly crucial in an era where data generation is exponential, driven by the proliferation of IoT devices, social media, and digital transactions. As businesses increasingly rely on data-driven insights to inform their strategies, understanding the intricacies of Apache Hadoop becomes essential for any computer enthusiast keen on exploring the frontiers of technology.
Key Takeaways
- Apache Hadoop is an open-source software framework for distributed storage and processing of large datasets.
- Hadoop is designed to handle big data processing by breaking down large datasets into smaller chunks and distributing them across a cluster of computers.
- Hadoop uses Hadoop Distributed File System (HDFS) for storage, which allows for reliable and scalable storage of large datasets across multiple machines.
- The distributed processing in Hadoop is achieved through the use of MapReduce, which allows for parallel processing of data across the cluster.
- Hadoop is known for its scalability, as it can easily add more nodes to the cluster to handle increasing amounts of data and processing requirements.
Big Data Processing with Apache Hadoop
The primary function of Apache Hadoop is to facilitate big data processing through its unique architecture. At the heart of this architecture lies the Hadoop Distributed File System (HDFS), which allows for the storage of large files across multiple machines. HDFS is designed to be fault-tolerant and highly available, ensuring that data remAIns accessible even in the event of hardware failures.
This resilience is critical for organizations that depend on continuous access to their data for real-time analytics and decision-making. Hadoop’s processing capabilities are powered by the MapReduce programming model, which breaks down tasks into two main functions: Map and Reduce. The Map function processes input data and produces a set of intermediate key-value pairs, while the Reduce function aggregates these pairs to produce the final output.
This model not only simplifies the programming process but also optimizes resource utilization by allowing tasks to run concurrently across different nodes in a cluster. As a result, organizations can process terabytes or even petabytes of data in a fraction of the time it would take using traditional methods.
Storage in Apache Hadoop

Storage in Apache Hadoop is primarily managed through HDFS, which is designed to handle large files efficiently. Unlike traditional file systems that store files in a hierarchical structure, HDFS breaks files into blocks (typically 128 MB or 256 MB) and distributes them across various nodes in a cluster. This block-based storage approach enhances data accessibility and fault tolerance, as multiple copies of each block can be stored on different nodes.
In the event of a node failure, HDFS can seamlessly retrieve data from another node that holds a replica, ensuring minimal disruption to operations. Moreover, HDFS is optimized for high-throughput access rather than low-latency access, making it ideal for batch processing tasks common in big data analytics. This design philosophy allows organizations to store vast amounts of unstructured and semi-structured data without worrying about the limitations imposed by traditional databases.
As a result, businesses can harness diverse data sources—ranging from social media feeds to sensor data—enabling them to derive valuable insights that drive innovation and competitive advantage.
Distributed Processing in Apache Hadoop
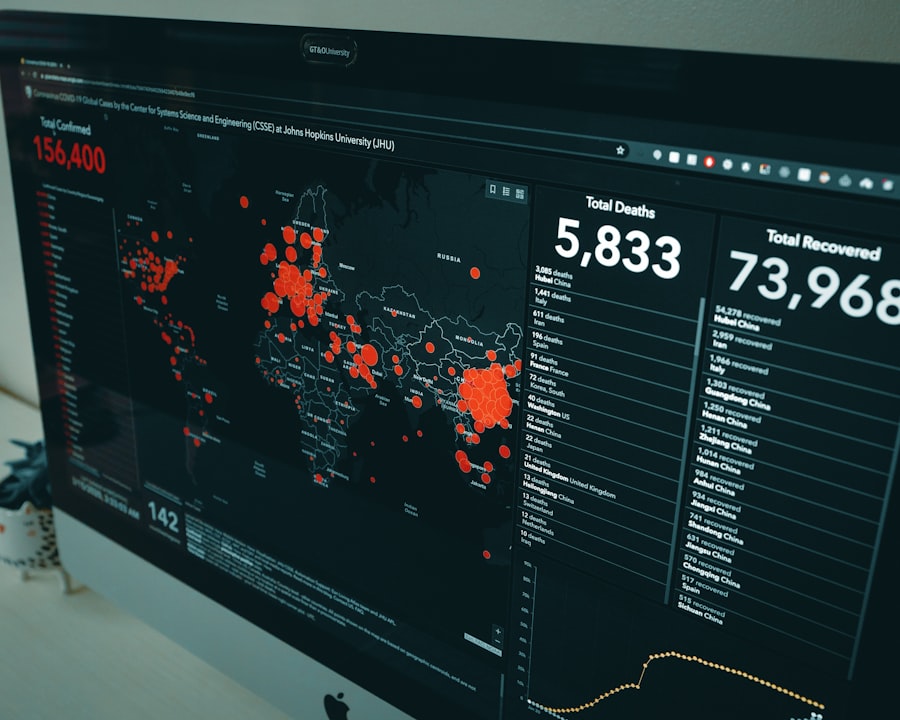
| Metrics | Value |
|---|---|
| Number of Nodes | 100 |
| Data Processed | 1 Petabyte |
| MapReduce Jobs | 5000 |
| Processing Time | 10 hours |
One of the standout features of Apache Hadoop is its ability to perform distributed processing across a cluster of machines. This capability is crucial for handling large-scale data sets that would be impractical to process on a single machine. By distributing tasks across multiple nodes, Hadoop can leverage the combined processing power of the cluster, significantly reducing the time required for data analysis.
The distributed nature of Hadoop also enhances its fault tolerance. If one node fails during processing, the system automatically reallocates tasks to other available nodes without interrupting the overall workflow. This self-healing capability ensures that data processing continues smoothly, even in the face of hardware failures.
Additionally, Hadoop’s architecture allows for horizontal scaling; organizations can easily add more nodes to their clusters as their data processing needs grow, making it a flexible solution for evolving business requirements.
Scalability in Apache Hadoop
Scalability is one of the defining characteristics that sets Apache Hadoop apart from traditional data processing frameworks. As organizations accumulate more data over time, they require systems that can grow alongside their needs without incurring prohibitive costs or complexity. Hadoop’s architecture is inherently designed for scalability; it allows users to add new nodes to their clusters with minimal disruption to ongoing operations.
This horizontal scaling capability means that organizations can start with a small cluster and expand it as their data volumes increase. Each new node added to the cluster contributes additional storage capacity and processing power, enabling organizations to handle larger workloads without compromising performance. Furthermore, because Hadoop runs on commodity hardware, businesses can achieve significant cost savings compared to proprietary solutions that require specialized equipment.
Resilience in Apache Hadoop
Resilience is a critical aspect of Apache Hadoop’s design philosophy. The framework’s ability to recover from hardware failures without losing data or halting processing is one of its most compelling features. HDFS achieves this resilience through data replication; each block of data is stored on multiple nodes within the cluster.
By default, HDFS creates three replicas of each block, ensuring that even if one or two nodes fail, the data remains accessible from other nodes. In addition to replication, Hadoop employs various mechanisms to monitor the health of nodes within the cluster. The NameNode, which manages metadata and namespace information for HDFS, continuously checks the status of DataNodes (the nodes that store actual data).
If a DataNode becomes unresponsive or fails, the NameNode automatically reassigns tasks and replicates any lost blocks to maintain data integrity and availability. This robust resilience makes Hadoop an attractive choice for organizations that require high levels of uptime and reliability in their data processing operations.
Use Cases for Apache Hadoop
The versatility of Apache Hadoop has led to its adoption across various industries and use cases. In the financial sector, for instance, banks and investment firms utilize Hadoop for fraud detection and risk management by analyzing vast amounts of transaction data in real-time. By leveraging machine learning algorithms on top of Hadoop’s processing capabilities, these organizations can identify suspicious patterns and mitigate risks more effectively.
In healthcare, Hadoop plays a pivotal role in managing patient records and genomic data analysis. Hospitals and research institutions use Hadoop to store and process large datasets generated from medical imaging, clinical trials, and patient monitoring systems. This enables them to derive insights that improve patient care and drive advancements in medical research.
Similarly, e-commerce companies harness Hadoop for customer behavior analysis, inventory management, and personalized marketing strategies by analyzing user interactions and purchase histories at scale.
Conclusion and Future of Apache Hadoop
As we look toward the future, Apache Hadoop continues to evolve alongside the rapidly changing landscape of big data technologies. While newer frameworks such as Apache Spark have gained popularity for their speed and ease of use in certain scenarios, Hadoop remains a foundational technology that underpins many big data ecosystems. Its ability to handle vast amounts of unstructured data efficiently ensures that it will remain relevant for years to come.
Moreover, as organizations increasingly adopt hybrid cloud strategies, Hadoop’s compatibility with cloud platforms enhances its appeal. The integration of Hadoop with cloud services allows businesses to scale their operations dynamically while benefiting from cost-effective storage solutions. As machine learning and artificial intelligence become more prevalent in data analytics, we can expect further innovations within the Hadoop ecosystem that will enable users to harness these advanced technologies seamlessly.
In conclusion, Apache Hadoop stands as a testament to the power of open-source collaboration in addressing complex challenges associated with big data processing. Its robust architecture, scalability, resilience, and diverse use cases make it an indispensable tool for organizations seeking to unlock the value hidden within their data assets. For computer enthusiasts eager to explore new technology projects, delving into Apache Hadoop offers an exciting opportunity to engage with one of the most influential frameworks shaping the future of data analytics today.
For those interested in the expansive capabilities of Apache Hadoop in handling big data, its distributed processing, and scalability, it’s essential to understand how these technologies are being integrated into new and emerging fields. One such intriguing application is in the realm of virtual environments, specifically within the metaverse. A related article that explores this intersection is “Tourism in the Metaverse: Who Needs Reality?” which discusses how big data and distributed processing technologies are crucial in creating scalable and resilient virtual worlds. You can read more about this fascinating topic and its implications by visiting Tourism in the Metaverse: Who Needs Reality?
This article provides insights into how big data frameworks like Hadoop could be pivotal in the development and expansion of metaverse environments.
FAQs
What is Apache Hadoop?
Apache Hadoop is an open-source software framework for distributed storage and processing of large datasets across clusters of computers. It provides a way to store, manage, and analyze big data.
What are the key features of Apache Hadoop?
Apache Hadoop offers features such as distributed processing, scalability, fault tolerance, and cost-effectiveness. It allows for the storage and processing of large volumes of data across clusters of commodity hardware.
How does Apache Hadoop handle big data processing?
Apache Hadoop uses a distributed processing model, where large datasets are divided into smaller chunks and processed in parallel across multiple nodes in a cluster. This allows for faster processing of big data compared to traditional single-node processing.
What is the role of Apache Hadoop in data storage?
Apache Hadoop provides a distributed file system called Hadoop Distributed File System (HDFS) for storing large datasets across multiple nodes in a cluster. This allows for reliable and scalable storage of big data.
How does Apache Hadoop achieve scalability?
Apache Hadoop achieves scalability by allowing users to easily add or remove nodes from the cluster as needed. This enables the system to handle growing amounts of data and processing demands without requiring significant changes to the infrastructure.
What is the resilience of Apache Hadoop?
Apache Hadoop is designed to be resilient to hardware failures and data corruption. It achieves this through data replication and fault tolerance mechanisms, ensuring that data remains available and intact even in the event of node failures.
What are some common use cases for Apache Hadoop?
Apache Hadoop is commonly used for tasks such as data warehousing, log processing, recommendation systems, fraud detection, and large-scale data analytics. It is particularly well-suited for processing and analyzing unstructured and semi-structured data.








Leave a Reply